- What’s there?
- Bernoulli and Binomial Distributions
- Poisson Distribution
- Categorical and Multinomial Distributions
- Sources
What’s there?
Like Foundations of Probability, I wanted to cover some more basics before Gaussians really quickly.
Why do I write this?
I wanted to create an authoritative document I could refer to for later. Thought that I might as well make it public (build in public, serve society and that sort of stuff).
Bernoulli and Binomial Distributions
Why together?
They form the basis for modeling any experiment with a binary outcome.
Foundation – The Single Trial
Bernoulli Trial
A single experiment with exactly two possible, mutually exclusive outcomes. These outcomes are generically labeled “success” and “failure”.
Bernoulli Distribution
A random variable
is said to follow a Bernoulli distribution if it is the outcome of a single Bernoulli trial.
The distribution is governed by a single parameter, ![p \in [0, 1]](https://s0.wp.com/latex.php?latex=p+%5Cin+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002)
Probability Mass Function (PMF): The PMF of a Bernoulli random variable is

This can be written more compactly as

Moments:
- Expectation:
- Variance:
![\mathbb{E}[X] = 1 \cdot p + 0 \cdot (1-p) = p](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX%5D+%3D+1+%5Ccdot+p+%2B+0+%5Ccdot+%281-p%29+%3D+p&bg=ffffff&fg=000&s=0&c=20201002)
![\text{Var}(X) = \mathbb{E}[X^2] - (\mathbb{E}[X])^2 = (1^2 \cdot p + 0^2 \cdot (1-p)) - p^2 = p - p^2 = p(1-p)](https://s0.wp.com/latex.php?latex=%5Ctext%7BVar%7D%28X%29+%3D+%5Cmathbb%7BE%7D%5BX%5E2%5D+-+%28%5Cmathbb%7BE%7D%5BX%5D%29%5E2+%3D+%281%5E2+%5Ccdot+p+%2B+0%5E2+%5Ccdot+%281-p%29%29+-+p%5E2+%3D+p+-+p%5E2+%3D+p%281-p%29&bg=ffffff&fg=000&s=0&c=20201002)
Foundation – Sum of Trials
Binomial Experiment
The Binomial distribution arises from extending the Bernoulli trial. It describes the outcome of an experiment that satisfies the following four conditions:
1. The experiment consists of a fixed number of trials,
.
2. Each trial is independent of the others.
3. Each trial has only two possible outcomes (success/failure).
4. The probability of success,, is the same for each trial.
Binomial Distribution
A random variable
is said to follow a Binomial distribution if it represents the total number of successes in
and the probability of success
.
Probability Mass Function (PMF): To find the probability of observing exactly 
- The probability of any specific sequence of
failures is
, due to independence.
- The number of distinct ways to arrange
. Combining these gives the PMF:

Moments: The Binomial random variable 

- Expectation:
- Variance:
![\mathbb{E}[K] = \mathbb{E}[\sum X_i] = \sum \mathbb{E}[X_i] = \sum p = np](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BK%5D+%3D+%5Cmathbb%7BE%7D%5B%5Csum+X_i%5D+%3D+%5Csum+%5Cmathbb%7BE%7D%5BX_i%5D+%3D+%5Csum+p+%3D+np&bg=ffffff&fg=000&s=0&c=20201002)
![\text{Var}(K) = \text{Var}[\sum X_i] = \sum \text{Var}[X_i] = \sum p(1-p) = np(1-p)](https://s0.wp.com/latex.php?latex=%5Ctext%7BVar%7D%28K%29+%3D+%5Ctext%7BVar%7D%5B%5Csum+X_i%5D+%3D+%5Csum+%5Ctext%7BVar%7D%5BX_i%5D+%3D+%5Csum+p%281-p%29+%3D+np%281-p%29&bg=ffffff&fg=000&s=0&c=20201002)
Poisson Distribution
The Poisson distribution can be derived as the limit of the Binomial distribution, 

Huh?
Imagine dividing a one-hour interval into 
Properties
Probability Mass Function (PMF):

The range of a Poisson variable is countably infinite. The term 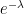
Moments:
- Expectation:
- Variance:
![\mathbb{E}[K] = \lambda](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BK%5D+%3D+%5Clambda&bg=ffffff&fg=000&s=0&c=20201002)

When is this even used? Predicting counts.
What if we want to predict the count of things? That is,
When the target variable in a regression problem is a count (e.g., number of purchases a customer makes in a month, number of clicks on an ad), standard linear regression is inappropriate.
Why?
A linear regression model doesn’t know the target variable is a count. It can easily predict negative values (e.g., -2 purchases) or fractional values (e.g., 4.7 clicks), which are nonsensical in this context.
Moreover, and this is important,
Linear regression assumes that the variability (variance) of the data points is the same regardless of their predicted value. Huh?
I have described a statistical property called heteroscedasticity, where the variability of a variable is unequal across the range of values of a second variable that predicts it.
In simpler terms, the data’s “spread” or “scatter” is not constant!
Standard linear regression assumes homoscedasticity. This means it expects the errors (the difference between the actual data points and the regression line) to have the same variance at all levels of the predictor variable.
Think of it as a consistent “error band” around the regression line. The amount of scatter should be roughly the same for small predicted values as it is for large ones.
Count data is often heteroscedastic. The variance tends to increase as the mean count increases. For instance, consider the example of daily website visitors –
- Small Personal Blog: The average number of visitors might be 10 per day. The daily count probably won’t vary much, maybe staying within a tight range like 5 to 15. The variance is low.
- Popular Website: The average might be 10,000 visitors per day. On a slow day, it might get 8,000, and on a viral day, it might get 15,000. The range of possible values is much wider, so the variance is high.
What do we do instead?
Poisson regression is used instead, where the response variable is assumed to follow a Poisson distribution, and the logarithm of its mean parameter 
- This distribution is defined only for non-negative integers, so the model’s underlying assumption matches the nature of the data.
- Also, a key property of the Poisson distribution is that its mean is equal to its variance, which naturally handles the issue of non-constant variance.
How does it work?
Instead of modeling the mean count directly, Poisson regression models the logarithm of the mean as a linear combination of the features.

Using the log ensures that the predicted mean, 
Categorical and Multinomial Distributions
These are the direct generalizations of the Bernoulli and Binomial distributions to experiments with more than two possible outcomes.
Foundation – The Single Multi-Class Trial
Categorical Trial:
This is a single experiment with
Categorical Distribution:
A random variable
The distribution is governed by a parameter vector ![\mathbf{p} = [p_1, \dots, p_K]^\top](https://s0.wp.com/latex.php?latex=%5Cmathbf%7Bp%7D+%3D+%5Bp_1%2C+%5Cdots%2C+p_K%5D%5E%5Ctop&bg=ffffff&fg=000&s=0&c=20201002)
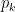

- Representation: The outcome is typically represented using one-hot encoding. A trial resulting in category
, where the 1 is in the
- Probability Mass Function (PMF): For a one-hot encoded vector
:

Foundation – Sum of Multi-Class Trials
Multinomial Experiment
This is an experiment consisting of
.
Multinomial Distribution
A random vector
follows a Multinomial distribution if each component
represents the total count for the
.
Probability Mass Function (PMF): The probability of observing exactly 




The first term is the multinomial coefficient, which counts the number of ways to arrange the outcomes.
Moments:
- Expectation:
- Variance:
(Each marginal is a Binomial)
- Covariance:
for
. The counts are negatively correlated because an increase in the count of one category must come at the expense of another.
![\mathbb{E}[X_k] = np_k](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX_k%5D+%3D+np_k&bg=ffffff&fg=000&s=0&c=20201002)
Sources
- Mathematics for Machine Learning (link)

Leave a reply to Gamma Family of Distributions – Vineeth Bhat Cancel reply