- What’s there?
- Introduction
- Stability under linear transformation
- Now, more introductions
- Marginals and Conditions
- Product of Gaussian Densities
- Sums and Linear Transformations of Gaussians
- Sources
What’s there?
Started with some Probability and Statistics; doing Gaussians now. This is an info dump.
Why do I write this?
I wanted to create an authoritative document I could refer to for later. Thought that I might as well make it public (build in public, serve society and that sort of stuff).
Introduction
Definition of a Univariate Gaussian
A random variable 

Properties
- Symmetry: The PDF is perfectly symmetric about its mean,
. This implies that the mean, median, and mode of the distribution are all equal.
- The Normalization Constant: The term
is the normalization constant. It ensures that the total area under the curve integrates to 1, as required for any valid PDF:

- The Standard Normal Distribution: A special case of the Gaussian with
and
is called the standard normal distribution, denoted
. Any Gaussian variable
can be transformed into a standard normal variable
via standardization:

68-95-99.7 Empirical Rule
I’m just adding this just like that.
- One Standard Deviation (
): Approximately 68.27% of the area under the curve lies within one standard deviation of the mean.

- Two Standard Deviations (
): Approximately 95.45% of the area under the curve lies within two standard deviations of the mean.

- Three Standard Deviations (
): Approximately 99.73% of the area under the curve lies within three standard deviations of the mean.

Stability under linear transformation
The Gaussian distribution is stable under affine transformations. If 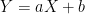



Therefore,.
![\mathbb{E}[Y] = \mathbb{E}[aX+b] = a\mathbb{E}[X]+b = a\mu + b](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BY%5D+%3D+%5Cmathbb%7BE%7D%5BaX%2Bb%5D+%3D+a%5Cmathbb%7BE%7D%5BX%5D%2Bb+%3D+a%5Cmu+%2B+b&bg=ffffff&fg=000&s=0&c=20201002)

Also, the sum of two independent Gaussian random variables is a Gaussian random variable.
Now, more introductions
The Multivariate Gaussian Distribution
A random vector 

We use the notation 
Let’s deconstruct this formula –
- Normalization Constant: The term
The termis the determinant of the covariance matrix, which geometrically represents the squared volume of the parallelepiped formed by the eigenvectors of
.
- The Exponential Argument: The term inside the exponent,
This quadratic form is known as the Mahalanobis distance squared. It measures the distance from a pointto the mean
, taking into account the covariance of the data. It is a unitless distance that accounts for the fact that the data cloud may be stretched and rotated.


The Geometry of the MVN
The loci of points with constant probability density (the isocontours) are the sets of

This is the equation of a hyperellipse centered at
Now, for understanding the geoemtry of the ellipse, do an eigendecomposition –

where 


- Principal Axes: The eigenvectors
of
- Axis Lengths: The eigenvalues
determine the spread along these axes. The length of the semi-axis along the direction
.
This means that the
MVN is a cloud of points whose main axes of variation are aligned with the eigenvectors of its covariance matrix.
Partitioning the vector
We begin with a joint Gaussian distribution over a high-dimensional random vector 



The joint distribution is defined by a partitioned mean vector and a partitioned covariance matrix:

where 


We can now ask two questions
- Marginalization: What is the distribution of one subset,
, if we have no information about the other?
- Conditioning: What is the distribution of one subset,
, if we observe the value of the other?
Marginals and Conditions
Marginals
To find the marginal distribution

The marginal distribution of a joint Gaussian is also a Gaussian.
The result of this integration is remarkably simple. We effectively just “read off” the corresponding parts from the joint distribution’s parameters:

Intuition: If you have a 2D Gaussian “mountain,” its shadow projected onto the x-axis (integrating out y) is a 1D Gaussian bell curve.
Conditionals
Remember that 
The conditional distribution of a joint Gaussian is also a Gaussian.
The derivation involves algebraic manipulation of the exponents of the Gaussian PDFs (completing the square).
Without going too much into the maths, I’ll offer the following results –
- Conditional Mean:

- Conditional Covariance:

Interpretation:
- The conditional mean is a linear function of the observed variable
and is adjusted based on how surprising the observation
). The adjustment is scaled by the correlation term
.
- The conditional covariance is independent of the observation
minus a positive semi-definite term that represents the information gained from the observation.
Product of Gaussian Densities
When applying Bayes’ theorem, we often need to multiply a Gaussian likelihood by a Gaussian prior. This product is also related to the Gaussian family.
Bayesian Inference Context
In a Bayesian setting, the posterior is proportional to the likelihood times the prior:

Yeah, this is just a fancy term.
What this is
The product of two Gaussian PDFs is an unnormalized Gaussian PDF.
Let’s consider two Gaussian densities (not necessarily normalized distributions) over the same variable

Their product is:

where the new covariance 

- New Covariance:
- New Mean:
- The term
is a scaling constant that does not depend on


Interpretation in terms of Information: The inverse of a covariance matrix is known as the precision matrix. The equations show that when multiplying Gaussians, we simply add their precisions. This aligns with the intuition that combining two sources of information results in a more precise (higher precision, lower variance) final belief. The new mean is a precision-weighted average of the original means.
Sums and Linear Transformations of Gaussians
Setting
We apply a linear (or more generally, affine) transformation to 

where 

We want to know
What is the distribution of
?
Vineeth tells you what’s up
An affine transformation of a Gaussian random variable is also a Gaussian random variable.
Computing the New Mean: We use the linearity of expectation:
Computing the New Covariance: We use the property of covariance under affine transformations:
Therefore, the distribution of the transformed variable
![\mathbb{E}[\mathbf{y}] = \mathbb{E}[\mathbf{A}\mathbf{x} + \mathbf{b}] = \mathbf{A}\mathbb{E}[\mathbf{x}] + \mathbf{b} = \mathbf{A}\boldsymbol{\mu} + \mathbf{b}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Cmathbf%7By%7D%5D+%3D+%5Cmathbb%7BE%7D%5B%5Cmathbf%7BA%7D%5Cmathbf%7Bx%7D+%2B+%5Cmathbf%7Bb%7D%5D+%3D+%5Cmathbf%7BA%7D%5Cmathbb%7BE%7D%5B%5Cmathbf%7Bx%7D%5D+%2B+%5Cmathbf%7Bb%7D+%3D+%5Cmathbf%7BA%7D%5Cboldsymbol%7B%5Cmu%7D+%2B+%5Cmathbf%7Bb%7D&bg=ffffff&fg=000&s=0&c=20201002)


Special Case: Sum of Independent Gaussians
If we have two independent Gaussian random variables, 


![\mathbf{x} = [X, Y]^\top](https://s0.wp.com/latex.php?latex=%5Cmathbf%7Bx%7D+%3D+%5BX%2C+Y%5D%5E%5Ctop&bg=ffffff&fg=000&s=0&c=20201002)
![\mathbf{A}=[1, 1]](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BA%7D%3D%5B1%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002)


The means add, and because of independence, the variances add.
Sources
- Mathematics for Machine Learning (link)

Leave a comment