What’s there?
Covers these things –
- Uniform & Exponential distributions
- Beta & Dirichlet (distributions over probabilities, key for Bayesian inference)
This should conclude stuff from continuous distributions that I wanted to talk about.
Why do I write this?
I wanted to create an authoritative document I could refer to for later. Thought that I might as well make it public (build in public, serve society and that sort of stuff).
Uniform
Wdym what’s uniform? We’ve already used it so many times.


Exponential
The Exponential distribution is a continuous distribution that models the time between events in a Poisson process.
Foundational insight
Recall that a Poisson process describes events occurring independently at a constant average rate, $\lambda$. The Poisson distribution counts the number of events in a fixed interval.
The Exponential distribution describes the waiting time for the very next event to occur.
Ok? Cool, I also want to say that it is memoryless.
The Exponential distribution is the only continuous distribution that is memoryless. This means that the probability of an event occurring in the next instant is independent of how much time has already elapsed. If you have been waiting for 10 minutes for a bus whose arrival follows an exponential distribution, the probability of it arriving in the next minute is exactly the same as it was when you first arrived. 
Theoretical development
Formal Definition: A continuous random variable 



The rate parameter 

Expectation (Mean): ![\mathbb{E}[T] = 1/\lambda](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BT%5D+%3D+1%2F%5Clambda&bg=ffffff&fg=000&s=0&c=20201002)

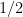
And, of course, the variance –

Beta
Ok, now we start the stuff that I really wanted to write this prose for.
Introduction
Beta and Dirichlet Distributions – They are not distributions over data itself, but distributions over the parameters of other distributions. This makes them essential tools for Bayesian inference.
The Beta distribution is a continuous distribution defined on the interval ![[0, 1]](https://s0.wp.com/latex.php?latex=%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002)
Foundations
We must talk about the Gamma Function.
It’s essentially the continuous form of the factorial. It is defined as –

The crucial connection between the Gamma function and the factorial is given by the identity for any positive integer n –

Properties of th Gamme function
- Recursion Formula: Similar to the factorial,

- Domain and Poles: The Gamma function is defined for all complex numbers except for non-positive integers (0, -1, -2, …), where it has simple poles. This means the function goes to infinity at these points.
- Special Values: While the Gamma function can be challenging to compute directly for many values, some special values are well-known. A particularly famous one is:

This is important and can be uses this further as,
.
First principles
Consider a Bernoulli trial (e.g., a coin flip) with an unknown probability of success, 
Formal Definition: A random variable 

![f(p | \alpha, \beta) = \frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)} p^{\alpha-1}(1-p)^{\beta-1}, \quad p \in [0,1]](https://s0.wp.com/latex.php?latex=f%28p+%7C+%5Calpha%2C+%5Cbeta%29+%3D+%5Cfrac%7B%5CGamma%28%5Calpha%2B%5Cbeta%29%7D%7B%5CGamma%28%5Calpha%29%5CGamma%28%5Cbeta%29%7D+p%5E%7B%5Calpha-1%7D%281-p%29%5E%7B%5Cbeta-1%7D%2C+%5Cquad+p+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=000&s=0&c=20201002)
where 


Interpretation of Hyperparameters: The hyperparameters 

is the power of
is the power of
(the probability of failure).
corresponds to a uniform distribution, representing complete prior uncertainty.
pushes the probability mass towards 1.
pushes the probability mass towards 0.
- Large
Conjugacy
Conjugacy: In Bayesian inference, a prior distribution is conjugate to a likelihood if the resulting posterior distribution belongs to the same family of distributions as the prior.
What? It means that if you choose a specific type of prior distribution (your initial belief) that “matches” your likelihood (the data you observe), your posterior distribution (your updated belief) will be the same type of distribution as your prior, just with updated parameters.
This gets us to the Beta-Bernoulli Model –
- Prior: We place a Beta prior on the unknown probability
.
- Likelihood: We observe data from a Bernoulli or Binomial process. Suppose we observe
successes and
failures. The likelihood is proportional to
.
- Posterior: According to Bayes’ theorem, the posterior is proportional to the likelihood times the prior:

This is the kernel of another Beta distribution. The posterior is:

Interpretation: The learning process is incredibly simple: we just add the observed counts of successes and failures to our prior pseudo-counts.
Dirichlet
The Dirichlet distribution is the multivariate generalization of the Beta distribution. It is a distribution over a probability vector.
First principles
- The Problem: Consider a Categorical or Multinomial trial with
possible outcomes and an unknown probability vector
, where
. The Dirichlet distribution models our uncertainty about this entire probability vector.
- The Simplex: The domain of the Dirichlet distribution is the standard
-simplex, which is the set of
- Formal Definition: A random vector
follows a Dirichlet distribution, denoted
, if its PDF is:

where the hyperparameter
is a vector of positive real numbers, which can be interpreted as pseudo-counts for each of the
Conjugacy, the Dirichlet-Multinomial Model
- Prior:
- Likelihood: We observe data from
trials, with counts
for each category. The likelihood is proportional to
.
- Posterior:
The posterior is another Dirichlet distribution:
As with the Beta, learning is a simple matter of adding the observed counts to the prior pseudo-counts.



Sources
- Mathematics for Machine Learning (link)

Leave a comment