What’s there?
While the Inverse Transform Sampling method provides a theoretical foundation for random sampling, its practical applicability is limited to distributions with an invertible Cumulative Distribution Function (CDF).
So, we have other stuff!
Why do I write this?
I wanted to create an authoritative document I could refer to for later. Thought that I might as well make it public (build in public, serve society and that sort of stuff).
Box-Muller Transform
We can use this to generate 
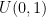
Foundational insight
Remeber that the CDF of the Gaussian distribution, which involves the error function (
What else did you expect? I will give more insights through theory – I don’t want to mention them directly here.
So, I really just wrote this section to mention what is called the Jacobian determinant.
Just remember that
In probability, density is “probability per unit area.” When you switch coordinate systems, the definition of a “unit area” changes.
We’ll get back to this.
Theoretical development
Let 


The expression 
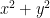
Sounds familiar?
Yes, we can use polar coordinates now! We can use 


We know that –
- Cartesian Area: A small rectangular area element,
, has the same size everywhere on the plane.
- Polar Area: A small “polar patch,”
, does not have a constant area. A patch with a large radius
is much bigger than a patch with a small radius, even if
and
are the same.
The fundamental relationship is that the probability in a small patch must be equal in both systems:


This is the working of the jacobian determinant. Using this, we get –

Algorithm
We see that the joint density factors into two parts: 
for
. This is the PDF of a uniform distribution.
for
. This is the PDF of a Rayleigh distribution.
The Box-Muller algorithm exploits this by generating samples for 
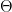
- Generate two independent uniform random variables
.
- Generate the angle
. This is a direct sample from the uniform distribution for the angle.
- Generate the radius
, follows an exponential distribution with rate
. We can use Inverse Transform Sampling to generate a sample for
:
. Thus,
.
- Convert back to Cartesian coordinates:


The resulting 

How to do this for any arbitrary thing?
To generate samples from an arbitrary Gaussian
, one simply generates a standard normal sample
using Box-Muller and then applies the linear transformation:
.
Duh.
Rejection Sampling
This is when we want to generate samples from 
It works by sampling from an easier-to-sample “proposal” distribution and then probabilistically accepting or rejecting those samples.
Setup
- Target Distribution,
that is proportional to
where the normalization constant
may be unknown.
- Proposal Distribution,
: A simpler distribution that we already know how to sample from (e.g., a uniform or Gaussian).
- Acceptance Constant,
: A constant chosen such that
for all
must form an “envelope” that is everywhere above our unnormalized target density.
Algorithm
- Propose: Draw a sample
from the proposal distribution,
.
- Evaluate: Calculate the acceptance ratio:
. This ratio is guaranteed to be in
.
- Accept/Reject: Draw a sample
from the standard uniform distribution,
.
- If
, accept the sample:
.
- If
, reject the sample and return to Step 1.
- If
Interpretation
Yeah, what is even happening here?
Imagine the graphs of
- Sample a point
uniformly from the area under the curve of the envelope
- If this point is also under the curve of the target density
This process correctly generates samples with a distribution of
Still don’t get it? Yeah, I didn’t either.
More intuition
For the dummies out there (like me!).
Imagine you want to sample random points from within the shape of an oddly-shaped pond (your complex target distribution), but you can only throw darts randomly at a large, rectangular tarp that covers the entire pond (your simple proposal distribution).
- Throw a Dart: You throw a dart, and it lands somewhere on the tarp. This is Step 1: Propose.
- Check Where it Landed: You look at the dart’s location.
- Accept or Reject:
- If the dart landed in the pond, you accept its location as a valid sample.
- If the dart landed on the tarp but outside the pond, you reject it and throw another dart.
If you do this many times, the collection of accepted dart locations will be a perfect random sample from within the shape of the pond.
This is just the most basic thing, not the algorithm.
The shapes now have varying heights.
- Propose (Throw a horizontal dart): When you draw a sample
from
- Accept/Reject (Throw a vertical dart): Now, at that horizontal position, you need to decide whether to keep the sample. This is done by throwing a “vertical” dart.
- The height of the dartboard at this position is
.
- The height of your target shape is
.
- The acceptance ratio
tells you how much of the dartboard’s height is “filled” by the target shape at that exact spot.
- You then draw a random number
- The height of the dartboard at this position is
This process ensures that you are more likely to accept samples in regions where the target distribution
Ok, why not accept all points with r < 1?
That is, with the acceptance ratio less than 1?
The proposal distribution, 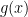
The random comparison, 
Think of the acceptance ratio, 
- Where the Target is High: In a region where
- Where the Target is Low: In a region where
This probabilistic step ensures that you keep more samples at the peaks and fewer samples in the valleys, perfectly sculpting the simple proposal distribution into the shape of your desired target distribution.
Makes sense? Yay!
Sources
- Mathematics for Machine Learning (link)

Leave a reply to Generating and Combining RVs – Vineeth Bhat Cancel reply