- What’s there?
- What are S, V and D?
- Theoretical development
- Applications
- Aside: Eckart-Young-Mirsky Theorem
- Aside: Intuitions for SVD
- Sources
What’s there?
There are basically 5 (ಐದು / पाँच) types of matrix decompositions that are like super important. I strive to go in depth into all of them. These are
- Eigendecomposition (Matrix Decompositions 1)
- QR decomposition (Matrix Decompositions 2)
- Cholesky decomposition (Matrix Decompositions 2)
- LU decomposition (Matrix Decompositions 2)
- (perhaps the most important) Singular Value Decomposition (This post!)
Why do I write this?
I wanted to create an authoritative document I could refer to for later. Thought that I might as well make it public (build in public, serve society and that sort of stuff).
What are S, V and D?
Singular, Value and Decomposition? Let’s start!
Geometric action of a matrix!
Remember eignedecomposition? Yes? No? See Matrix Decompositions 1
What if the matrix is not square?? We use SVD! Wait lemme explain:
Any linear transformation 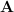
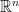

This is the main geometric insight of the SVD –
This hyperellipse lies within a subspace of the codomain. The SVD provides a complete characterization of this transformation by identifying the specific orthonormal basis vectors in the input space that are mapped directly onto the principal axes of this resulting hyperellipse.
Formal definition!!
Theorem (Singular Value Decomposition): For any matrix
of rank
, there exists a factorization of the form:
where the components have the following properties:
is an Orthogonal Matrix. The columns of
, denoted
, are the left-singular vectors. They form an orthonormal basis for the output space (codomain),
of these vectors,
, form an orthonormal basis for the column space (range) of
is an Orthogonal Matrix. The columns of
, denoted
, are the right-singular vectors. They form an orthonormal basis for the input space (domain),
, form an orthonormal basis for the row space of
is a Rectangular Diagonal Matrix. The only non-zero entries of
are on its main diagonal. These entries,
, are the singular values of
The number of non-zero singular values is exactly the rank
is the length of the
-th principal semi-axis of the output hyperellipse.

Woah! Column space, row space? What?
Actually, I’ll call this –
An Exposition on the Fundamental Subspaces of a Linear Transformation
The most profound insights into the nature of this transformation are revealed by analyzing four special vector subspaces that are intrinsically associated with the matrix
Subspace 1: The Column Space (or Range)
The column space of a matrix
or
, is the set of all possible linear combinations of its column vectors. If the columns of
, where each
, then:
$latex \text{Col}(\mathbf{A}) = \text{span}{\mathbf{a}1, \dots, \mathbf{a}_n} = \left{ \sum{j=1}^n c_j \mathbf{a}_j \mid c_j \in \mathbb{R} \right}$
Notice how the column space is the set of all vectors 
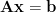
Subspace 2: The Null Space (or Kernel)
The null space of a matrix
or
, is the set of all solutions to the homogeneous linear system
.

The null space answers the question: “What is the set of all input vectors that get crushed or annihilated by the transformation?”
For a system 

The null space thus describes the ambiguity or non-uniqueness of the solution.
Subspace 3: The Row Space
It is equivalent to the column space of
.
Subspace 4: The Left Null Space
The left null space of a matrix
.

It is called the “left” null space because the equation can be written as 
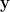
Notice how the left null space contains all vectors in the output space that are orthogonal to every vector in the column space.
It represents the part of the codomain that is “unreachable” by the transformation.
The Rank-Nullity Theorem
Theorem (Rank-Nullity Theorem): For any matrix

or, using the definition of rank:

Interpretation: The dimension of the input space (
The Fundamental Theorem of Linear Algebra
Part 1: Dimensions
By applying the Rank-Nullity theorem to both




Part 2: Geometry
- The row space and the null space are orthogonal complements in the input space
- The column space and the left null space are orthogonal complements in the output space
Theoretical development
From eigendecomposition
Consider the matrix 



By the Spectral Theorem, any real symmetric matrix has a full set of orthonormal eigenvectors and real, non-negative eigenvalues. Therefore,

where 

Now, substitute the SVD form 

Since 

Comparing this with the eigendecomposition 
- The right-singular vectors of
.
- The eigenvalues of
.
A symmetric argument applies to the matrix 

This reveals that:
- The left-singular vectors of
.
- The non-zero eigenvalues of
.
Singular values and geometry
The relationship between the components can be summarized by the singular value equations, derived by right-multiplying

Considering this equation one column at a time, for 

This equation provides the geometric interpretation:
- The linear transformation
- The scaling factor is the
Reduced SVD
What if 

- Full SVD: The form described above, where
and
.
- Reduced SVD: If
, the matrix
rows of all zeros. These rows, when multiplied by

where
,
(now a square diagonal matrix), and
. This is a more memory-efficient representation.
Applications
Low-Rank Approximation and Principal Component Analysis (PCA)
The expression 




What does this mean? You select the ones corresponding to the largest singular values:) This is what’s used in PCA! (PCA, Spectral Clustering and t-SNE)
Moore-Penrose Pseudoinverse and Linear Regression
For any matrix 

In ML: The solution to the linear least-squares problem, 

Numerical Stability and Condition Number
Remember? I spoke about this in Matrix Decompositions 2? Condition number, that is.
The condition number of a matrix 

Aside: Eckart-Young-Mirsky Theorem
Matrix norms
Spectral Norm: The maximum scaling factor the matrix can apply to any unit vector: 

Frobenius Norm: The matrix equivalent of the vector Euclidean norm, defined as the square root of the sum of the squares of all its elements: 

Theorem
Let the SVD of 





The approximation error is given by:


This theorem guarantees that truncating the SVD provides the most compact linear approximation of a matrix for a given rank, capturing the “most important parts of M” by retaining the components with the largest singular values.
Aside: Intuitions for SVD
I highly suggest looking up Six (and a half) intuitions for SVD, but here are some things that aren’t directly covered earlier in this blog:
Theoretical development for Moore-Pensore inverse
We substitute the SVD of

By defining a change of variables 




The minimum is achieved when 






where 
Listing the intuitions
We have mostly coverered all of these above btw,
- Rotations and Scalings (The Geometric Picture)
- Best Rank-k Approximations
- Least Squares Regression
- Input and Output Directions
- Lost & Preserved Information
- PCA and Information Compression
Yay, we are (mostly) done with matrix decompositions!

Leave a reply to Other important matrix bits – Vineeth Bhat Cancel reply