What’s there?
There are basically 5 (ಐದು / पाँच) types of matrix decompositions that are like super important. I strive to go in depth into all of them. These are
- Eigendecomposition (Matrix Decompositions 1)
- QR decomposition (This post!)
- Cholesky decomposition (This post!)
- LU decomposition (This post!)
- (perhaps the most important) Singular Value Decomposition
Why do I write this?
I wanted to create an authoritative document I could refer to for later. Thought that I might as well make it public (build in public, serve society and that sort of stuff).
QR Decomposition
Basics?
Yeah, you remember vector spaces and orthogonality? Yeah, that’s it.
Ok, what is it?
A factorization of a matrix 
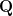

Definition (QR Decomposition): Let 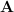
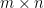

where:
, where
is the
identity matrix.
for
).
- R? Right? Right-upper? And Q preceded R? Get it? Idk.
Ok, but why?
Orthogonal matrices are awesome.
QR decomposition formalizes a process of transforming an arbitrary basis (the columns of
How do I do it?
Gram-Schmidt process!
This handout from UCLA is awesome. I have realised that I’m not made out of time and want to make these notes more for intuition and rigorous math only for places that I deem super important (around ~50%).
Applications!!
This is why I do this – yayyy (first time I got to this section in under ~20 minutes).
- Solving Linear Systems and Least-Squares Problems
- In robotics?
Solving Linear Systems and Least-Squares Problems
Say we want to solve 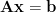

Since 


This new system is trivial to solve because 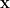
Now, for the linear least squares regression.
The objective is to find the vector

That means, for us,

How did we do this? Orthogonal transformations preserve the Euclidean norm!!!
Very cool and smart sounding, right? But, why did we do this?
The main issue lies with the formation of 
A condition number is a score that measures how sensitive a function or a matrix is to small changes in its input.
This means that –
- A low condition number means a matrix is well-conditioned. Small changes in the input data will only cause small changes in the output or solution. This is stable and reliable.
- A high condition number means a matrix is ill-conditioned. Tiny, insignificant changes in the input data can cause huge, dramatic changes in the solution. This is unstable and unreliable.
In numerical calculations, an ill-conditioned matrix can amplify tiny rounding errors into completely wrong answers.
Forming the matrix
![cond(\mathbf{A}^\top\mathbf{A}) = [cond(\mathbf{A})]^2](https://s0.wp.com/latex.php?latex=cond%28%5Cmathbf%7BA%7D%5E%5Ctop%5Cmathbf%7BA%7D%29+%3D+%5Bcond%28%5Cmathbf%7BA%7D%29%5D%5E2&bg=ffffff&fg=000&s=0&c=20201002)
This means that if your original matrix
The QR method is superior because it cleverly bypasses the need to form the unstable
- Decomposition: First, it decomposes the original matrix
, where
- Stable Transformation: The next step uses a key property of orthogonal matrices: they don’t change the length (Euclidean norm) of vectors when they multiply them. This allows the problem to be transformed without amplifying errors:

This transformation is numerically stable because the condition number of
In Robotics?
Literally anywhere you use least squares. Example – Levenberg-Marquardt algorithm in inverse kinematics:)
Cholesky decomposition
Axiomatic basis
We do have something for this!
The entire theory of Cholesky decomposition rests upon the properties of Symmetric Positive Definite (SPD) matrices. Let 
- Symmetry: The matrix is symmetric if it is equal to its transpose,
. This means
for all
(the more you know!).
- Positive Definiteness: A symmetric matrix
, the quadratic form
is strictly positive.

Key Properties of SPD Matrices:
- All eigenvalues of an SPD matrix are real and strictly positive.
- All diagonal elements (
) are strictly positive.
- The matrix is always invertible (since no eigenvalue is zero).
Proofs!
What is it?
Let

where:
is a lower triangular matrix with strictly positive diagonal entries (
).
is the transpose of
Isn’t this very specific?
So, why do we need this?
Ee often need to generate random samples from a multivariate Gaussian distribution 

How do we use it?
- Generate Standard Normal Variates: Generate a vector
where each component
is an independent sample from the standard normal distribution
. This vector
has a mean of
and a covariance matrix of
.
- Decompose: Compute the Cholesky factor
.
- Transform: Create the desired sample

This works because the mean and covariance of the transformed variable
.
.
The Cholesky decomposition provides the correct linear transformation
LU decomposition
Definition
The LU decomposition of a square matrix

where 

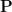
How do I do it?
Remember how Guassian elimination does elementary operations? And, these elementary operations can be written as elementary matrices? So, we can do –

Now, if you work it out – the elementary matrices will be lower triangular and their product will also be lower triangular. A nice property is that these lower triangular elementary matrices is that their product is also simple: the multipliers 

Now, what if one of the pivots is 0? Or like, super small – leading to instability?
To prevent this, we perform pivoting: swapping the current row with a subsequent row that has a larger pivot element.
Each row swap can be represented by left-multiplication with a permutation matrix
This factorization exists for any square matrix
Applications
Literally any decomposition can help Solving Linear Systems easier. I’m gonna skip this but that’s the primary use (again).
Other than that, the decomposition provides an efficient way to calculate the determinant.

(since it is unit triangular).
(the product of its diagonal elements).
, where
is the number of row swaps performed.
Therefore,.
Sources
- Mathematics for Machine Learning (link)

Leave a comment