What’s there?
There are basically 5 (ಐದು / पाँच) types of matrix decompositions that are like super important. I strive to go in depth into all of them. These are
- Eigendecomposition (This post!)
- QR decomposition
- Cholesky decomposition
- LU decomposition
- (perhaps the most important) Singular Value Decomposition
Edit (July 20, 2025): Added proof of spectral theorem.
Why do I write this?
I wanted to create an authoritative document I could refer to for later. Thought that I might as well make it public (build in public, serve society and that sort of stuff).
Eigen decomposition
Wait…
Basics!
Linear Transformation
A linear transformation is a function
between two vector spaces
and
that preserves the operations of vector addition and scalar multiplication. For finite-dimensional vector spaces, any linear transformation
can be represented by an
matrix
. The action of the transformation on a vector
is given by matrix-vector multiplication:
.
Ok, got it? Basic linear algebra.
Eigenvectors and eigenvalues
Let
be a square matrix. A nonzero vector
is an eigenvector of
such that
. The scalar
is called the eigenvalue corresponding to the eigenvector
.
I will now add a bit of geometry. The equation states that the vector 
- If
, the eigenvector is stretched.
- If
, the eigenvector is compressed.
- If
, the eigenvector is flipped and scaled.
- If
, the eigenvector is unchanged.
- If
, the eigenvector is mapped to the zero vector, meaning it lies in the null space of
Want a reminder on how to find these? The expression 

Important matrix types
Ok, this is purely LLM generated.
- Diagonal Matrices (
): Square matrices where all non-diagonal entries are zero (
for
). They represent pure scaling along the coordinate axes. Their powers (
) and inverses (
) are trivial to compute.
- Triangular Matrices (
): Square matrices that are either lower triangular (
, where
for
) or upper triangular (
, where
for
). Systems of equations involving triangular matrices can be solved efficiently via forward or backward substitution.
- Orthogonal Matrices (
): Square matrices whose columns (and rows) form an orthonormal basis. They satisfy the property
, which implies
. Geometrically, orthogonal matrices represent pure rotations or reflections, which preserve lengths and angles of vectors:
.
I wrote this (!!) –
- Also, Diagonalizability. A square matrix
Eigendecomposition
Basics
Ok, we can start now. For eigen decompositions, we are super concerned with endomorphisms. This is when the domain and the codomains of the linear transformation are in the same space. This is basically – 
Why do you need to know this? You don’t. I knew this and barfed the information on you.
When can you eigendecompose?
If a matrix 
is a matrix whose columns are the
.
is a diagonal matrix whose diagonal entries are the corresponding eigenvalues,
.
is the inverse of the matrix
. The existence of
Ok, why can you eigendecompose?
Let 


We can concatenate these equations into a single matrix equation. Let ![\mathbf{P} = [\mathbf{p}_1, \dots, \mathbf{p}_n]](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BP%7D+%3D+%5B%5Cmathbf%7Bp%7D_1%2C+%5Cdots%2C+%5Cmathbf%7Bp%7D_n%5D&bg=ffffff&fg=000&s=0&c=20201002)
![\mathbf{A}\mathbf{P} = \mathbf{A}[\mathbf{p}_1, \dots, \mathbf{p}_n] = [\mathbf{A}\mathbf{p}_1, \dots, \mathbf{A}\mathbf{p}_n] = [\lambda_1\mathbf{p}_1, \dots, \lambda_n\mathbf{p}_n]](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BA%7D%5Cmathbf%7BP%7D+%3D+%5Cmathbf%7BA%7D%5B%5Cmathbf%7Bp%7D_1%2C+%5Cdots%2C+%5Cmathbf%7Bp%7D_n%5D+%3D+%5B%5Cmathbf%7BA%7D%5Cmathbf%7Bp%7D_1%2C+%5Cdots%2C+%5Cmathbf%7BA%7D%5Cmathbf%7Bp%7D_n%5D+%3D+%5B%5Clambda_1%5Cmathbf%7Bp%7D_1%2C+%5Cdots%2C+%5Clambda_n%5Cmathbf%7Bp%7D_n%5D&bg=ffffff&fg=000&s=0&c=20201002)
The right-hand side can be expressed as the product of
![[\lambda_1\mathbf{p}_1, \dots, \lambda_n\mathbf{p}_n] = [\mathbf{p}_1, \dots, \mathbf{p}_n] \begin{bmatrix} \lambda_1 & 0 & \dots & 0 \\ 0 & \lambda_2 & \dots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \dots & \lambda_n \end{bmatrix} = \mathbf{P}\mathbf{D}](https://s0.wp.com/latex.php?latex=%5B%5Clambda_1%5Cmathbf%7Bp%7D_1%2C+%5Cdots%2C+%5Clambda_n%5Cmathbf%7Bp%7D_n%5D+%3D+%5B%5Cmathbf%7Bp%7D_1%2C+%5Cdots%2C+%5Cmathbf%7Bp%7D_n%5D+%5Cbegin%7Bbmatrix%7D+%5Clambda_1+%26+0+%26+%5Cdots+%26+0+%5C%5C+0+%26+%5Clambda_2+%26+%5Cdots+%26+0+%5C%5C+%5Cvdots+%26+%5Cvdots+%26+%5Cddots+%26+%5Cvdots+%5C%5C+0+%26+0+%26+%5Cdots+%26+%5Clambda_n+%5Cend%7Bbmatrix%7D+%3D+%5Cmathbf%7BP%7D%5Cmathbf%7BD%7D&bg=ffffff&fg=000&s=0&c=20201002)
Thus, we have the relationship 
Side Note: Notice how
Eigendecomposition is powerful!
Eigendecomposition reveals fundamental properties of a matrix:
- Determinant: The determinant of

- Trace: The trace of

- Matrix Powers: Eigendecomposition simplifies the computation of matrix powers.

The Spectral Theorem for Symmetric Matrices
Ok, here’s a special case – what if the matrix is symmetric? (Why do we care about symmetric matrices? Remind yourself about covariance matrices.)
Theorem (Spectral Theorem): For any real symmetric matrix
- All eigenvalues of
- There exists an orthonormal basis of
consisting of the eigenvectors of
Proof 1: Eigenvalues are Real
Let
Now, take the conjugate transpose (denoted by a star, 


Since the matrix 

Next, we right-multiply this equation by the original eigenvector

Now, let’s return to the original equation, 

By comparing Eq. 1 and Eq. 2, we can see that:


The term 

A number is equal to its own complex conjugate if and only if it is a real number. This completes the proof that all eigenvalues of a real symmetric matrix are real.
Proof 2: Eigenvectors of Distinct Eigenvalues are Orthogonal
Let 
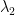




Let’s start with the first equation and left-multiply by 

Now, let’s take the transpose of the entire expression. Since the result is a scalar, it is equal to its own transpose:


Because 

Next, we return to the second original equation (


By comparing Eq. 3 and Eq. 4, we get:


We started with the assumption that the eigenvalues are distinct, so 

This shows that the eigenvectors
Yeah, that’s it.
Cool, now think about eigendecomposition.

This form has a powerful geometric interpretation: any transformation by a symmetric matrix can be understood as a sequence of three operations:
- A rotation back to the original coordinate system (
- A rotation or reflection (
) to align the coordinate system with the eigenvectors.
- A scaling along these new axes by the eigenvalues (multiplication by
“Huh?”, you ask. Yeah, the above order is wrong.
When you apply the transformation 
- Rotation/Reflection (
- Scaling (
- Rotation Back (
Cool, ok, but where do I use it?
I point you back to the “Eigendecomposition is powerful!” subsection.
Sources
- Mathematics for Machine Learning (link)

Leave a reply to PCA, Spectral Clustering and t-SNE – Vineeth Bhat Cancel reply