What’s there?
Basic principles of information theory – entropy, KL divergence.
Why do I write this?
I wanted to create an authoritative document I could refer to for later. Thought that I might as well make it public (build in public, serve society and that sort of stuff).
Entropy
Brain dump
The Concept of Information (or “Surprisal”): The foundational idea is that learning the outcome of an event is more “informative” if that event was unlikely.
Axioms for an Information Measure: Shannon proposed that a measure of information, 

- Information is non-negative:
.
- If an event is certain (
), its information content is zero:
.
- If an event is less likely, it is more informative: if
, then
.
- The information gained from observing two independent events is the sum of their individual information contents:
.
The Information Formula: The unique function that satisfies these axioms is the negative logarithm:

The base of the logarithm, 
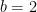

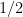

Theoretical development
- Formal Definition (Entropy): Let
be a discrete random variable that can take on
possible states
with probabilities
. The Shannon entropy of the random variable
or
, is:
![H(X) = \mathbb{E}[I(P(X))] = \sum_{k=1}^K p_k I(p_k) = -\sum_{k=1}^K p_k \log p_k](https://s0.wp.com/latex.php?latex=H%28X%29+%3D+%5Cmathbb%7BE%7D%5BI%28P%28X%29%29%5D+%3D+%5Csum_%7Bk%3D1%7D%5EK+p_k+I%28p_k%29+%3D+-%5Csum_%7Bk%3D1%7D%5EK+p_k+%5Clog+p_k&bg=ffffff&fg=000&s=0&c=20201002)
By convention, 
- Properties of Entropy:
- Minimum Entropy: The entropy is minimal (
) when there is no uncertainty. This occurs when one outcome is certain (
for some
) and all others are impossible (
for
).
- Maximum Entropy: The entropy is maximal when there is the most uncertainty. For a variable with
for all
.
- Geometric Interpretation: Entropy measures the “flatness” or “peakedness” of a probability distribution. A peaked distribution has low entropy; a flat distribution has high entropy.
- Minimum Entropy: The entropy is minimal (
Cross-Entropy
Theory
- Formal Definition (Cross-Entropy): Let
be the true probability distribution over a set of events, and
be our model’s predicted probability distribution over the same set of events. The cross-entropy of
![H(P, Q) = \mathbb{E}_{X \sim P}[I(Q(X))] = \sum_{k=1}^K p_k I(q_k) = -\sum_{k=1}^K p_k \log q_k](https://s0.wp.com/latex.php?latex=H%28P%2C+Q%29+%3D+%5Cmathbb%7BE%7D_%7BX+%5Csim+P%7D%5BI%28Q%28X%29%29%5D+%3D+%5Csum_%7Bk%3D1%7D%5EK+p_k+I%28q_k%29+%3D+-%5Csum_%7Bk%3D1%7D%5EK+p_k+%5Clog+q_k&bg=ffffff&fg=000&s=0&c=20201002)
Notice the structure: we are averaging the information content of the model’s probabilities (
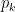
What does this mean?
Think about encoding the letters of the English alphabet into Morse code.
- True Distribution (
- Model Distribution (
Cross-entropy is the average length of the messages you’d have to send using your inefficient, ‘Z’-focused code to communicate actual English text. Because your code is optimized for the wrong reality, your messages will be, on average, much longer than necessary.
The extra length is the “penalty” for your incorrect assumption.
Deconstructing the formula –
The cross-entropy of

Let’s break this down:
: The true probability of an event
. This acts as a weight. We care more about events that actually happen often.
: This relates to the “cost” of encoding event
is high), the cost is low. If it says an event is very unlikely (
: We sum this “weighted cost” over all possible events to get the average cost, or the cross-entropy.
Relationship with KL Divergence
Cross-entropy is intimately related to Shannon entropy and the Kullback-Leibler (KL) Divergence, which measures the “extra” bits/nats needed due to using the wrong code.

Cross-Entropy = Entropy + KL Divergence.
This is like super important, since
In machine learning, the true data distribution
is equivalent to minimizing the KL divergence
. Therefore, cross-entropy serves as an excellent loss function.
Kullback-Leibler (KL) Divergence
Theory
Let
- For discrete distributions:
- For continuous distributions:
With cross entropy
As shown earlier,
.


The KL divergence (the penalty) is the difference between the average message length using the wrong code (
) and the average message length using the optimal code (
Minimizing and maximising
- Minimizing
- Minimizing
: This is the “reverse KL” used in Variational Inference. It forces
Um, what?
Mode Covering
This version asks, “What’s the penalty for my model
- The Penalty: Look at the term
. If there is a place where the true probability is high (
) but your model assigns it a near-zero probability (
), the ratio
becomes huge. The logarithm of this huge number is also huge, resulting in an infinite KL divergence.
- Behavior (“Zero-Avoiding”): To avoid this infinite penalty, the model is forced to place some probability mass everywhere the true distribution has mass. It learns to avoid assigning zero probability where it shouldn’t.
- Result (“Mode-Covering”): If the true distribution
Mode Seeking
This version flips the question and asks, “What’s the penalty for my model
- The Penalty: The formula for reverse KL is
. Now, consider a place where your model assigns some probability (
), but the true probability is zero (
). The ratio
becomes infinite, again leading to an infinite KL divergence.
- Behavior (“Zero-Forcing”): To avoid this infinite penalty, the model is forced to have zero probability wherever the true distribution has zero probability. It learns to only place probability mass in regions where it’s sure the true distribution exists.
- Result (“Mode-Seeking”): If the true distribution
Mutual Information
Understanding
How much does knowing the value of variable
reduce my uncertainty about variable
Recall that entropy,
. Mutual Information is simply the reduction in uncertainty.
Theory
The Mutual Information between two random variables
, is defined as:
where
is the conditional entropy.
In terms of KL Divergence
is the true joint distribution of the two variables, capturing all dependencies between them.
is the hypothetical joint distribution that we would have if the two variables were perfectly independent.
- Therefore, the Mutual Information is the KL divergence from the independent case to the true joint case. It measures how much the true joint distribution deviates from the assumption of independence. If the variables are truly independent, then
, and the KL divergence is zero.



Sources
- Mathematics for Machine Learning (link)

Leave a comment