What’s there?
This one explores some more distributions – Gamma, Chi-Squared, and Student’s t-distributions. Why?
- The Gamma distribution provides a flexible model for positive continuous random variables, such as waiting times.
- The Chi-Squared and Student’s t-distributions are special cases and transformations derived from the Gamma and Normal distributions.
Why do I write this?
I wanted to create an authoritative document I could refer to for later. Thought that I might as well make it public (build in public, serve society and that sort of stuff).
Gamma
It is a continuous distribution defined on the positive real line. This just means that it’s defined for 
Foundations
We’ve described the gamma function in Uniform, Exponential, Beta & Dirichlet. As a recap, it is,

Back to the topic, what are we even trying to do? What’s the intuitive goal?
We want to model the waiting time until the
-th event occurs in a Poisson process with a rate of
.
Recall the Exponential distribution models the waiting time for the first event. The Gamma distribution generalizes this to the sum of waiting times for multiple events.
Before everything, I just want to recap Poisson from Fundamental Discrete Probability Distributions.
The Poisson distribution is a statistical tool used to model the probability of a certain number of events happening within a fixed interval of time or space, provided these events occur at a known constant average rate and independently of the time since the last event.
For instance, “How many emails will I receive in the next hour?”
Where:
- k is the number of events you are interested in (e.g., 5 phone calls).
- λ (lambda) is the average number of events per interval (e.g., an average of 3 phone calls per hour).
- e is Euler’s number (approximately 2.71828).
- k! is the factorial of k.

Theory
Formal Definition: A continuous random variable 


The distribution is governed by two parameters:
- Shape parameter (
): Controls the shape of the distribution. For
, the density is monotonically decreasing. For
, it has a single peak. As
, the Gamma distribution approaches a Normal distribution.
- Rate parameter (
): Controls the scale of the distribution (inverse of the scale parameter).
- Moments:
- Expectation:
- Variance:
- Expectation:
- Relationship to other distributions:
- If
, the Gamma distribution becomes the Exponential distribution:
.
- The sum of
independent
variables is a
variable.
- The Chi-Squared distribution is a special case of the Gamma distribution.
- If
![\mathbb{E}[X] = \alpha/\beta](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX%5D+%3D+%5Calpha%2F%5Cbeta&bg=ffffff&fg=000&s=0&c=20201002)

Why is this cool?
The sum of independent Gamma-distributed random variables with the same rate parameter is also a Gamma-distributed variable. Specifically, if 

The shape parameters add, while the rate parameter remains the same.
Chi-Squared (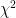 )
)
First principles
- The Core Definition: Let
be
. The Chi-Squared distribution with
, is the distribution of the sum of the squares of these variables:
- Degrees of Freedom (

Fundamental theorems of calculus
First one
If 

![[a, b]](https://s0.wp.com/latex.php?latex=%5Ba%2C+b%5D&bg=ffffff&fg=000&s=0&c=20201002)

Second one
If 


Ok, cool, what if 
If you have an integral of the form:

Its derivative with respect to

As a special case of Gamma
Step 1: Find the distribution of
where
.
We can derive this using the change of variables technique. Let
be the CDF of
. For
:
This probability is the integral of the standard normal PDF,
, between
and
:


We find the pdf using the Leibniz Integral rule –

Now, we compare this PDF to the Gamma PDF, 
We need to match the terms.
- The exponential term
suggests the rate parameter is
.
- The polynomial term
suggests that the shape parameter is
.
Let’s check if the normalization constant matches. For, the constant is
. It is a known property of the Gamma function that
. So the constant is
.
This matches perfectly. Therefore, we have proven that the square of a single standard normal variable follows a Gamma distribution:

A Chi-Squared distribution with one degree of freedom is identical to this Gamma distribution: 
Step 2: Find the distribution of 
Since each 

By definition, 

Where is this distribution used?
Example 1: Testing the Variance of a Population (Goodness-of-Fit)
- Scenario: A manufacturer produces bolts that are supposed to have a diameter variance of
. To perform quality control, a sample of
bolts is taken, and their sample variance is calculated to be
. Does this provide significant evidence that the true variance of the manufacturing process has increased?
- Application: Under the null hypothesis that the population is normal and the true variance is indeed
, the test statistic:

follows a Chi-Squared distribution with
degrees of freedom. We can then compare this value to the
distribution. We would calculate the probability
. If this probability (the p-value) is very low (e.g., < 0.05), we would reject the null hypothesis and conclude that the manufacturing process variance has likely increased.
Example 2: Likelihood-Ratio Tests in Machine Learning
- Scenario: In machine learning, we often want to compare two nested models: a simpler model (e.g., linear regression) and a more complex model that includes the simpler one as a special case (e.g., polynomial regression). We want to know if the additional complexity of the second model provides a statistically significant improvement in fit.
- Application: Let
be the maximum likelihood value for the simple model and
be the maximum likelihood for the complex model. The likelihood-ratio test statistic is:

According to Wilks’s theorem, as the number of data points becomes large, this statistic
approximately follows a Chi-Squared distribution. The degrees of freedom
We will discuss this later as well under statistics.
Student’s t-
Why does this exist?
Z-statistic
The formula
is a way to standardize the sample mean. It tells us how many standard errors our sample mean (
) is away from the true population mean (
). If we know the true population standard deviation (
), this Z-score will perfectly follow a standard normal distribution (a bell curve with a mean of 0 and a standard deviation of 1). T
This is wonderful because the properties of the normal distribution are well-understood, making it easy to calculate probabilities and test hypotheses.
But, we know neither
This is where the Student’s t-distribution comes in. It was developed specifically to solve this problem.
Since we don’t know the population standard deviation (
). We then substitute
To account for this added uncertainty, the t-statistic doesn’t follow a perfect normal distribution. Instead, it follows a t-distribution.
Theoretical development
Formal Definition: Let
be a Chi-Squared random variable with
and
are independent, then the random variable
defined as:
follows a Student’s t-distribution with
.
Derivation of the t-statistic: In the context of the sample mean, we have
. Substituting these into the definition of
This statistic, which uses the sample standard deviation
degrees of freedom.
Importantly,
- The t-distribution approaches the standard normal distribution as the degrees of freedom
. This makes sense: as the sample size grows, our estimate
Where is it used?
- Machine Learning (t-SNE): As discussed previously, the t-distribution with one degree of freedom is used in the low-dimensional space of t-SNE to create embeddings where clusters are more clearly separated. Its heavy tails are the key to this property.
- Hint for Hypothesis Testing: The t-distribution is the basis for the Student’s t-test, one of the most widely used statistical tests. It is used to compare the means of two groups, or to test whether a sample mean is significantly different from a hypothesized value, when the population variance is unknown. The t-statistic
is calculated, and its value is compared to the critical values of the t-distribution to determine statistical significance. It is the go-to tool for inference on means with small sample sizes.



Sources
- Mathematics for Machine Learning (link)

Leave a comment