What’s there?
An exposition (I love this word sm) into techniques of Inverse Transform Sampling and the algebra of random variables.
Why do I write this?
I wanted to create an authoritative document I could refer to for later. Thought that I might as well make it public (build in public, serve society and that sort of stuff).
Inverse Transform Sampling
This is how you generate random samples from any probability distribution.
Foundations
Y’know the standard uniform distribution, 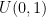
![[0, 1]](https://s0.wp.com/latex.php?latex=%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002)
We assume the existence of a pseudorandom number generator (PRNG) that can produce such samples.
Imma also just recap the properties of the CDF (
- It is a non-decreasing function.
- It is right-continuous.
and
. Tts range is therefore the interval
Intuition
A simple observation – if we apply the CDF of a random variable 


So cool.
Theoretical development
Theorem (Probability Integral Transform): Let 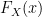
Proof: We want to find the CDF of 

![y \in [0, 1]](https://s0.wp.com/latex.php?latex=y+%5Cin+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002)

Since 


By the definition of the CDF of 

The CDF of the random variable 
Importantly, note the strictly monotonic CDF bit!
Algorithm
- Generate a uniform sample: Draw a random number
from the standard uniform distribution,
.
- Apply the inverse CDF: Compute the value
.
- Result: The resulting value
is a random sample from the distribution with CDF
When does this not work?
This requires the CDF to be invertible. What if it isn’t? Example – for Guassians (the most predominant stuff). Update – Advanced Methods for generating RVs
Sums and Products of Random Variables
What do we need to do?
Let 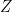


Sum of independent RVs
To find the distribution of the sum, we first find its CDF, 



Wut. How can we even compute this. Yeah, dw, we use independence and say that their joint density is the product of their marginal densities, 
We also differentiate – since the PDF is the derivative of the CDF (wrt 

(I derive the product one properly to give better understanding, btw.)
Important Special Cases:
- Sum of Gaussians: The sum of two independent Gaussian random variables is also a Gaussian. If
and
, then
. This is a rare case where the convolution has a simple, closed-form solution.
- Sum of Poissons: The sum of two independent Poisson random variables is also a Poisson. If
and
, then
.
Product of independent RVs
Define the product
The CDF of 

Since 

To make this integral solvable, we need to set explicit limits. The inequality 



Define the CDF properly
- When
- When
This allows us to rewrite the CDF as:

We can express the inner integrals in terms of the CDF of 
![F_Z(z) = \int_{0}^{\infty} f_X(x) F_Y(z/x) \,dx + \int_{-\infty}^{0} f_X(x) [1 - F_Y(z/x)] \,dx](https://s0.wp.com/latex.php?latex=F_Z%28z%29+%3D+%5Cint_%7B0%7D%5E%7B%5Cinfty%7D+f_X%28x%29+F_Y%28z%2Fx%29+%5C%2Cdx+%2B+%5Cint_%7B-%5Cinfty%7D%5E%7B0%7D+f_X%28x%29+%5B1+-+F_Y%28z%2Fx%29%5D+%5C%2Cdx&bg=ffffff&fg=000&s=0&c=20201002)
Find the PDF
The PDF, 
![f_Z(z) = \frac{d}{dz}F_Z(z) = \frac{d}{dz}\int_{0}^{\infty} f_X(x) F_Y(z/x) \,dx + \frac{d}{dz}\int_{-\infty}^{0} f_X(x) [1 - F_Y(z/x)] \,dx](https://s0.wp.com/latex.php?latex=f_Z%28z%29+%3D+%5Cfrac%7Bd%7D%7Bdz%7DF_Z%28z%29+%3D+%5Cfrac%7Bd%7D%7Bdz%7D%5Cint_%7B0%7D%5E%7B%5Cinfty%7D+f_X%28x%29+F_Y%28z%2Fx%29+%5C%2Cdx+%2B+%5Cfrac%7Bd%7D%7Bdz%7D%5Cint_%7B-%5Cinfty%7D%5E%7B0%7D+f_X%28x%29+%5B1+-+F_Y%28z%2Fx%29%5D+%5C%2Cdx&bg=ffffff&fg=000&s=0&c=20201002)
![f_Z(z) = \int_{0}^{\infty} f_X(x) \frac{d}{dz}F_Y(z/x) \,dx + \int_{-\infty}^{0} f_X(x) \frac{d}{dz}[1 - F_Y(z/x)] \,dx](https://s0.wp.com/latex.php?latex=f_Z%28z%29+%3D+%5Cint_%7B0%7D%5E%7B%5Cinfty%7D+f_X%28x%29+%5Cfrac%7Bd%7D%7Bdz%7DF_Y%28z%2Fx%29+%5C%2Cdx+%2B+%5Cint_%7B-%5Cinfty%7D%5E%7B0%7D+f_X%28x%29+%5Cfrac%7Bd%7D%7Bdz%7D%5B1+-+F_Y%28z%2Fx%29%5D+%5C%2Cdx&bg=ffffff&fg=000&s=0&c=20201002)
Using the chain rule, the derivative of 

Substituting this back into our expression:


For the first integral, 


Sources


Leave a comment