- What’s there?
- Axioms of Probability
- Random Variables
- Conditional Probability, Independence, and the Chain Rule
- Bayes’ Theorem
- Expectation, Variance and Moments
- Covariance and correlation
- Law of Large Numbers (LLN)
- Central Limit Theorem (CLT)
- Sources
What’s there?
I want to cover like some basics of probability before I get into Gaussians. Saliently, this covers LLN and CLT.
Why do I write this?
I wanted to create an authoritative document I could refer to for later. Thought that I might as well make it public (build in public, serve society and that sort of stuff).
Axioms of Probability
Imma just drone on about theory in this post.
Sample Space (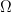

Event Space (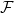

- The empty set is included:
.
- Closure under complementation: If an event
, then its complement
is also in
- Closure under countable unions: If
is a countable sequence of events in
Probability Measure (
- Non-negativity: The probability of any event is non-negative.

- Normalization (Unit Measure): The probability of the entire sample space is 1. This means that some outcome is guaranteed to occur.

- Countable Additivity (or
for
), the probability of their union is the sum of their individual probabilities.

Random Variables
A random variable
is a function
that assigns a real number to every possible outcome
The key technical requirement is that this function must be measurable, which ensures that sets of the form
are valid events in
PDF and PMF
The behavior of a discrete random variable is described by its PMF, 


The PMF satisfies 

The probability that a continuous random variable takes on any single specific value is zero. Instead, we describe its behavior with a PDF, 
![[a, b]](https://s0.wp.com/latex.php?latex=%5Ba%2C+b%5D&bg=ffffff&fg=000&s=0&c=20201002)

The PDF satisfies 

Also gonna throw this in here
A random variable is mixed if it has properties of both discrete and continuous variables.
Its probability distribution is a mixture of a PMF (for the discrete parts) and a PDF (for the continuous parts).
Conditional Probability, Independence, and the Chain Rule
Conditional Probability: The conditional probability of event
occurring, given that event
has already occurred, is denoted
. It represents an update to our belief about
Geometrically, this is a re-normalization of the probability space: we restrict our attention to the outcomes within event

Statistical Independence: Two events

Substituting this into the definition of conditional probability yields the more common test for independence:
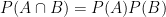
Two random variables 

Chain Rule
In the language of random variables, for a set of variables 

Bayes’ Theorem
Bayes’ theorem provides a formal mechanism for inverting conditional probabilities.
Terminology
- Hypothesis (
): A proposition about the world whose truth we are uncertain about (e.g., “The patient has the disease,” “This email is spam”).
- Evidence (
): A new piece of data or observation that is relevant to the hypothesis.
- Prior (
): Our initial belief in the hypothesis before observing the evidence.
- Likelihood (
): The probability of observing the evidence if the hypothesis were true. This is the forward, generative model.
- Posterior (
): Our updated belief in the hypothesis after observing the evidence. This is the quantity we want to compute.
The theorem itself
- The Marginal Likelihood (or Evidence): The denominator,
, is the total probability of observing the evidence, averaged over all possible hypotheses. It is computed using the law of total probability:
. It acts as a normalization constant, ensuring that the posterior probabilities sum to one.
The theorem can be written in a more memorable form using the terms:


Expectation, Variance and Moments
Imma just skip the basic stuff.
This is the Expectation of a Function –
![\mathbb{E}[g(X)] = \sum_{x} g(x) \, p(x) \quad \text{or} \quad \int_{-\infty}^{\infty} g(x) \, f(x) dx](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bg%28X%29%5D+%3D+%5Csum_%7Bx%7D+g%28x%29+%5C%2C+p%28x%29+%5Cquad+%5Ctext%7Bor%7D+%5Cquad+%5Cint_%7B-%5Cinfty%7D%5E%7B%5Cinfty%7D+g%28x%29+%5C%2C+f%28x%29+dx&bg=ffffff&fg=000&s=0&c=20201002)
Moments
Moments about the Origin: The 

![\mu'_k = \mathbb{E}[X^k]](https://s0.wp.com/latex.php?latex=%5Cmu%27_k+%3D+%5Cmathbb%7BE%7D%5BX%5Ek%5D&bg=ffffff&fg=000&s=0&c=20201002)
The first moment, ![\mu'_1 = \mathbb{E}[X]](https://s0.wp.com/latex.php?latex=%5Cmu%27_1+%3D+%5Cmathbb%7BE%7D%5BX%5D&bg=ffffff&fg=000&s=0&c=20201002)
Central Moments (Moments about the Mean): The 
![\mu_k = \mathbb{E}[(X - \mu)^k]](https://s0.wp.com/latex.php?latex=%5Cmu_k+%3D+%5Cmathbb%7BE%7D%5B%28X+-+%5Cmu%29%5Ek%5D&bg=ffffff&fg=000&s=0&c=20201002)
Random facts about central moments
- The first central moment is always zero:
.
- The second central moment,
, is the variance. It is the most important measure of the spread or dispersion of the distribution. It is denoted
or
. The standard deviation,
, is the square root of the variance, returned to the original units of the variable.
- The third central moment (normalized) is related to the skewness, which measures the asymmetry of the distribution.
- The fourth central moment (normalized) is related to the kurtosis, which measures the “tailedness” or propensity for outliers.
Covariance and correlation
We’ve discussed covariance in PCA, Spectral Clustering and t-SNE.
Now, notice that the magnitude of the covariance is difficult to interpret because it depends on the units and variances of the individual variables.
A covariance of 100 might be very strong for one pair of variables but very weak for another.
To create a standardized, unit-free measure of the linear relationship, we normalize the covariance by the standard deviations of the two variables. This gives the Pearson correlation coefficient,
–
: Perfect positive linear relationship.
: Perfect negative linear relationship.
: No linear relationship (uncorrelated).

Law of Large Numbers (LLN)
It says that that the average of a large number of independent samples from a distribution converges to the theoretical expected value of that distribution.
It is the theorem that guarantees that sampling works.
Theoretical Development: Forms of the Law
Weak Law of Large Numbers: This law states that for any arbitrarily small positive number 


This is also called convergence in probability. It doesn’t guarantee that for a single long experiment the average will be close to the mean, but that it is overwhelmingly likely to be.
Strong Law of Large Numbers: This law makes a much stronger statement. It asserts that, with probability 1, the sample mean will converge to the true mean.

This is also called almost sure convergence. This guarantees that for a single, infinitely long experiment, the sample average will eventually settle down at the true population mean.
Why is this important in ML?
The LLN is the theoretical justification for Empirical Risk Minimization.
When we minimize a loss function on a finite training set, we are computing an empirical average. The LLN gives us confidence that, with enough data, this empirical risk will be a good approximation of the true expected risk over the entire data distribution.
Central Limit Theorem (CLT)
Foundations
- The Question: The LLN tells us where the sample mean
is going (it converges to
). The CLT tells us how it gets there: it describes the shape of the probability distribution of the sample mean around the true mean for a large but finite
- The Setup: Let
be a sequence of i.i.d. random variables with finite mean
Theoretical Development
Theorem (Central Limit Theorem): As the sample size 

More formally, the standardized version of the sample mean converges in distribution to a standard normal distribution:

Why’s this so cool?
- The CLT is incredibly powerful because it holds true regardless of the shape of the original distribution of the
. Whether the individual variables are from a uniform, Bernoulli, exponential, or any other well-behaved distribution, the distribution of their average will always tend towards a Gaussian bell curve.
- This theorem explains the ubiquity of the Gaussian distribution in nature and science.
Many complex phenomena can be modeled as the sum or average of many small, independent random effects. According to the CLT, the distribution of this aggregate phenomenon will be approximately Gaussian, even if the individual effects are not. For example, measurement error in an instrument is often the sum of many small, independent sources of error, so it is well-modeled by a Gaussian.
Basically, Gaussians are common and this can be exploited.
Sources
- Mathematics for Machine Learning (link)

Leave a comment