- What’s there?
- Affine Spaces
- Inner Products (of functions)
- Orthogonal Projections
- Matrix Approximation
- Sources
What’s there?
I want to try and cover every other kinda trivial / small things related to matrices / LinAlg in this. This covers
- Affine spaces (This post!)
- Inner products of functions (This post!)
- Orthogonal projections (This post!)
- Matrix approximation (This post!)
- Rotations and quaternions
Why do I write this?
I wanted to create an authoritative document I could refer to for later. Thought that I might as well make it public (build in public, serve society and that sort of stuff).
Affine Spaces
Definition(s)
An affine space 


- For any point
,
.
- For any point
,
.
- For any two points
, there exists a unique vector
such that
. This unique vector is denoted
.
The vector space
Some other definitions
Affine Subspaces: An affine subspace 
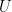

where
is a support point (an origin for the subspace) and
is the direction space. A vector space is a special case of an affine subspace where the support point is the origin.
Parametric Representation: If the direction space 


Examples include lines (
) and planes (
). A hyperplane is an affine subspace of codimension 1 (i.e., of dimension
in an
-dimensional space).
Affine Mappings: An affine map 

where
is the matrix of the underlying linear map and
is a translation vector.
Very math stuff – what’s the use?
Use 1: Support Vector Machines!
The separating hyperplane in a Support Vector Machine (SVM) is actually an affine subspace!
In a 
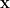

Here, 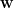

Inner Products (of functions)
Starting from dot products
The concept of an inner product on a space of functions is a direct generalization of the dot product on finite-dimensional Euclidean space 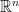
- The dot product in
. It satisfies the axioms of an inner product: bilinearity, symmetry, and positive definiteness.
- Now, a function
can be conceptualized as an infinite-dimensional vector, where each point
corresponds to a component with value
. In this view, the discrete sum of the dot product becomes a continuous integral.
- Further, to ensure the integrals are well-defined, we consider a vector space of functions, typically the space of square-integrable functions on an interval
, denoted
.
Formal Definition: The inner product of two real-valued functions 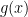

More generally, a weight function 

Theoretical Development
Gonna info dump some things –
- Induced Norm: The inner product induces a norm, known as the
-norm, which measures the “length” or “magnitude” of a function:

- Orthogonality of Functions: Two functions
and
are orthogonal if their inner product is zero:

- Orthogonal Basis and Fourier Series: A set of functions
is an orthogonal basis if its members are mutually orthogonal.
Where can I see this in action?
Use 1: Fourier Series
Functional analysis says that many well-behaved functions can be represented as a linear combination of orthogonal basis functions.
E.g., Fourier series, which represents a periodic function as a sum of sines and cosines, which form an orthogonal set on the interval ![[-\pi, \pi]](https://s0.wp.com/latex.php?latex=%5B-%5Cpi%2C+%5Cpi%5D&bg=ffffff&fg=000&s=0&c=20201002)
The coefficient for each basis function
is found by projecting
.
Other than this, you can actually show that solutions relating to Kernel methods, unknown functions in robotics (e.g., friction), etc. can be written as inner products of functions.
Orthogonal Projections
What is it, exactly?
An orthogonal projection is a mapping that takes a vector and finds its closest point within a given subspace.
It is the formalization of the geometric idea of casting a shadow.
Ok, find, but what is it?
Given a vector space 


The solution to this minimization problem occurs when the “error” vector, 


This is basically the Geometric Condition!
Two Cases
You can either
- Project onto a line, or,
- Project onto a subspace
Projection onto a Line: The simplest case is projecting a vector 


The projection is thus
. In matrix form for the standard dot product in
.
Hold up here. Notice that
is a vector. This is the vector of the projection. The magnituge of the projection, just the “size” of the shadow so to say, is the complement.

Projection onto a Subspace: This generalizes to projecting onto a subspace 
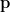




This is the normal equation. Solving for

The projection matrix is
. If the columns of
, and the formula simplifies to
.
Wait this doesn’t make sense directly:( Ok, imma write it again!
Projection onto a subspace
Yes, its own section.
Concept Projection onto a Line (1D) Projection onto a Subspace (nD) The “Ground” A single line defined by one vector b. A “floor” or subspace defined by multiple basis vectors, which are the columns of a matrix A. The “Shadow” The projection p is on the line, so it’s a scaled version of b. The projection p is on the “floor,” so it’s a linear combination of the basis vectors in A. Orthogonality The error vector (b – p) must be orthogonal to the line’s direction vector b. The error vector (b – p) must be orthogonal to the entire subspace. This means it must be orthogonal to every column of A.
Now, let’s derive!
State the Goal: We want to find the projection
Use the Orthogonality Condition: The error vector (

Substitute 

Solve for the Coefficients 


Now, solve for the coefficient vector

This formula gives us the perfect “recipe” of coefficients to create the projection.
Find the Projection Vector

The projection matrix is the part that does all the work:
Where have we seen this?
The solution to the least-squares problem, 

This solution,
, is the orthogonal projection of the observed target vector
onto the column space of the design matrix
.
Matrix Approximation
I just wanted to add this as a heading since it’s not directly evident that this is just the EYM theorem discussed in depth within Matrix Decompositions 3. Anyway, here’s the statement again –
Theorem (Eckart-Young-Mirsky): Let the SVD of a matrix 







The theorem states that to get the best approximation, one should keep the components corresponding to the largest singular values and discard the rest. The singular values quantify the “importance” of each rank-one component.
Applications
Gosh, what’s not there?
- Machine Learning (Principal Component Analysis): PCA is the most direct application of this theorem. It seeks the best rank-$k$ approximation of a centered data matrix. The SVD provides both the optimal subspace (spanned by the first $k$ right-singular vectors) and the coordinates of the data projected onto it.
- Machine Learning (Recommender Systems): A user-item rating matrix is often very large, sparse, and assumed to be approximately low-rank. Low-rank matrix factorization, which is a form of matrix approximation, is used to fill in the missing entries. The SVD finds the optimal low-rank approximation, uncovering latent factors that describe user preferences and item characteristics.
- AI (Natural Language Processing – Topic Modeling): In Latent Semantic Analysis (LSA), a large term-document matrix is constructed. Its low-rank approximation via SVD is used to find a “semantic space” where terms and documents with similar meanings are close together. The singular vectors represent abstract “topics.”
Sources
- Mathematics for Machine Learning (link)

Leave a comment